За последние лет семь gRPC уже всем уши прожужжали. И только самые ловкие разработчики могли избежать реализации взаимодействия с какой-нибудь системой по gRPC.
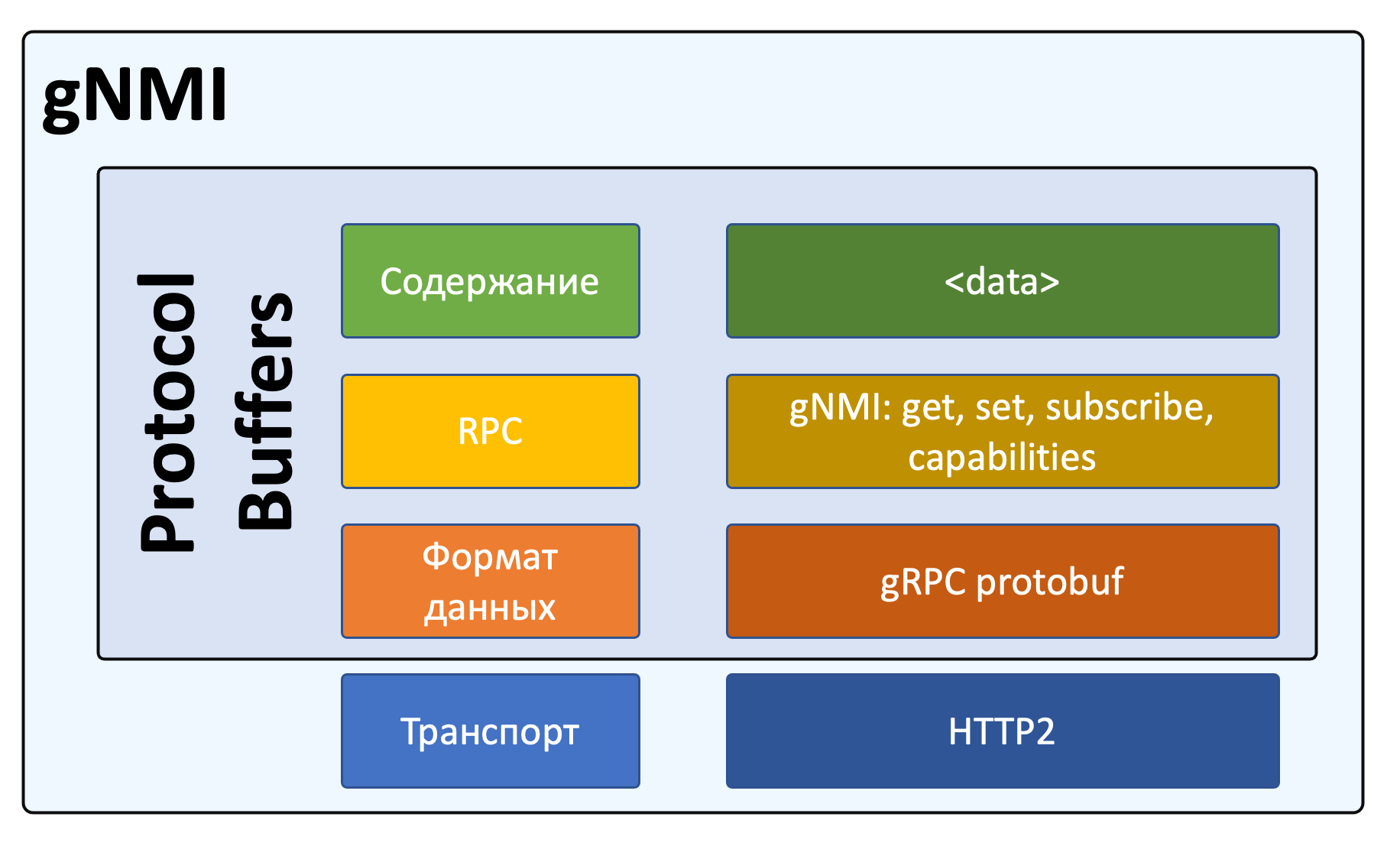
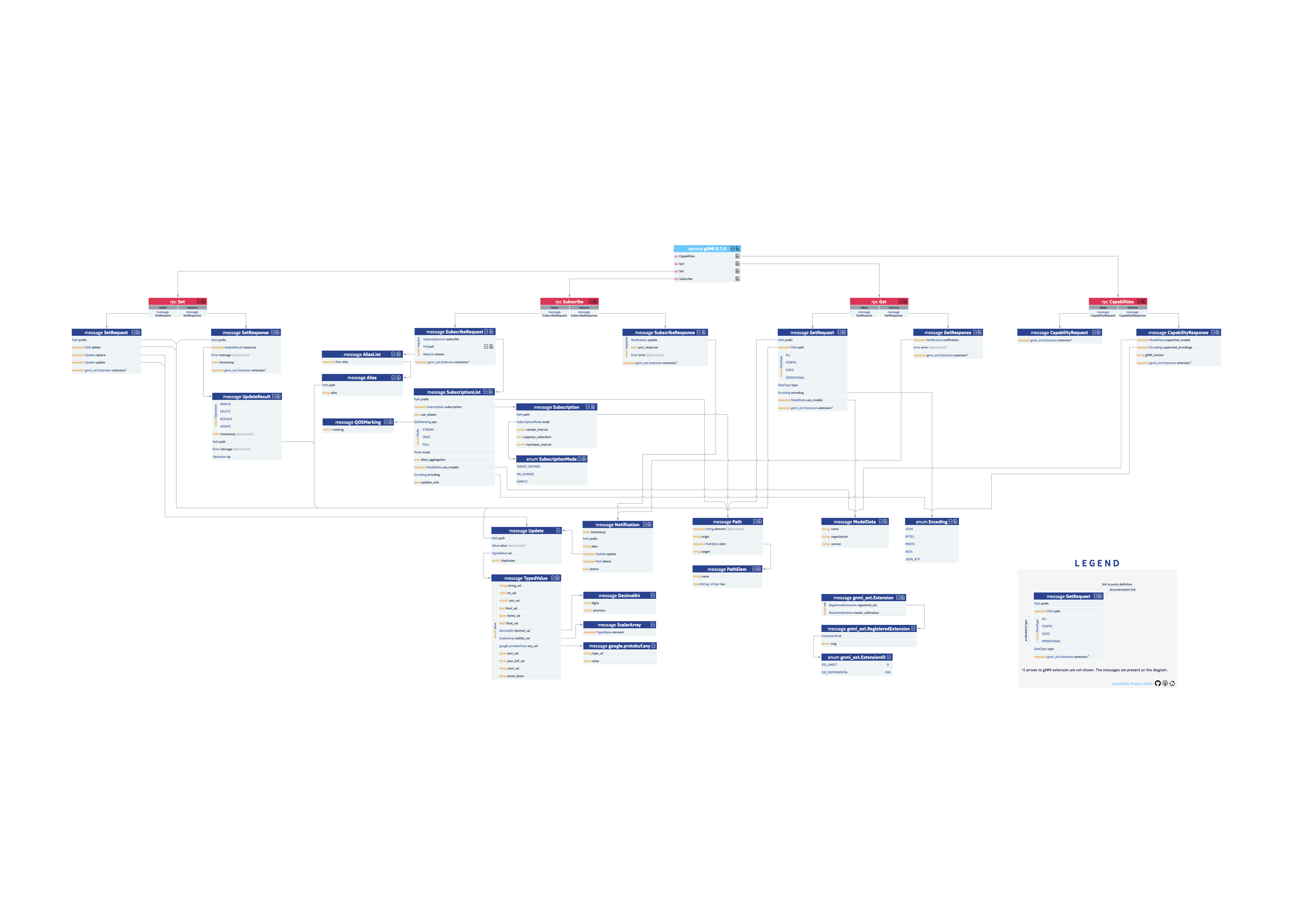
Реализация фреймворка поверх gRPC в мире сетевой автоматизации получила название gNMI - gRPC Network Management Interface.
В основе gNMI лежит gRPC, для моделирования данных использует YANG (но не обязательно), внутри уже определяются конкретные RPC. Кроме того gNMI изначально предоставляет возможность естественным образом реализовать telemetry - потоковую передачу телеметрических данных.
В любом случае я не я, если перед gNMI я не разберу gRPC. Поэтому простите за отступление, но без него статья превратится в бесполезное поверхностное хауту.
Сначала определяем сервис - Ping. А в нём есть метод - SendPingReply - это собственно и есть RPC - та самая процедура, которую мы дёрнем удалённо - процедура отправить PingReply.
В качестве атрибута она принимает параметр PingRequest, а вернёт ответ PingReply.
А что такое эти PingRequest и PingReply??
messagePingRequest{stringpayload=1;}
PingRequest - это одно из пересылаемых сообщений между клиентом и сервером.
Так объявляется факт его существования, и его содержимое. В этом случае внутри сообщения передаётся одно поле payload типа string.
payload - это произвольное имя, которое мы можем выбрать, как хотим.
string - определение типа.
1 - позиция поля в сообщении - для нас не имеет значения.
messagePingReply{stringmessage=1;}
Всё точно то же самое. Именем поля может быть даже слово message.
Вот так будет выглядеть полный proto-файл:
syntax="proto3";optiongo_package="go-server/ping";packageping;// The ping service definition.servicePing{// Sends a ping replyrpcSendPingReply(PingRequest)returns(PingReply){}}// The request message containing the ping payload.messagePingRequest{stringpayload=1;}// The response message containing the ping replaymessagePingReply{stringmessage=1;}
То есть именно вот так и выглядит спецификация, описывающая схему данных на обеих сторонах. И сервер и клиент будут использовать один и тот же proto-файл и всегда знать, как разобрать то, что отправила другая сторона. Даже если они написаны на разных языках.
Сохраняем как protos/ping.proto - он будет один для всех.
Ну ладно спецификация есть. И что с ней теперь делать?
А теперь мы напишем пинг-клиент на Python, а пинг-сервер на Go.
Сразу после этого в каталоге, где мы это выполнили, появятся два файла: ping_pb2.py и ping_pb2_grpc.py - это сгенерированный код.
Если вы зяглянете вовнутрь, то обнаружите там кучу классов. Это классы, реализующие сообщения, сервисы для сервера (PingServicer) и для клиента (PingStub). Там же у класса Ping есть и метод SendPingReply. И куча других штуковин.
Эти файлы нам никогда не придётся менять вручную - мы будем их только импортировать и использовать.
Очевидно, что эти py-файлы это только реализация интерфейса взаимодействия. Ровным счётом ничего тут не говорит, как этот сервис будет работать.
Бизнес-логика описывается уже отдельно - и вот она делается нами.
Клиент будет совсем бесхитростным.
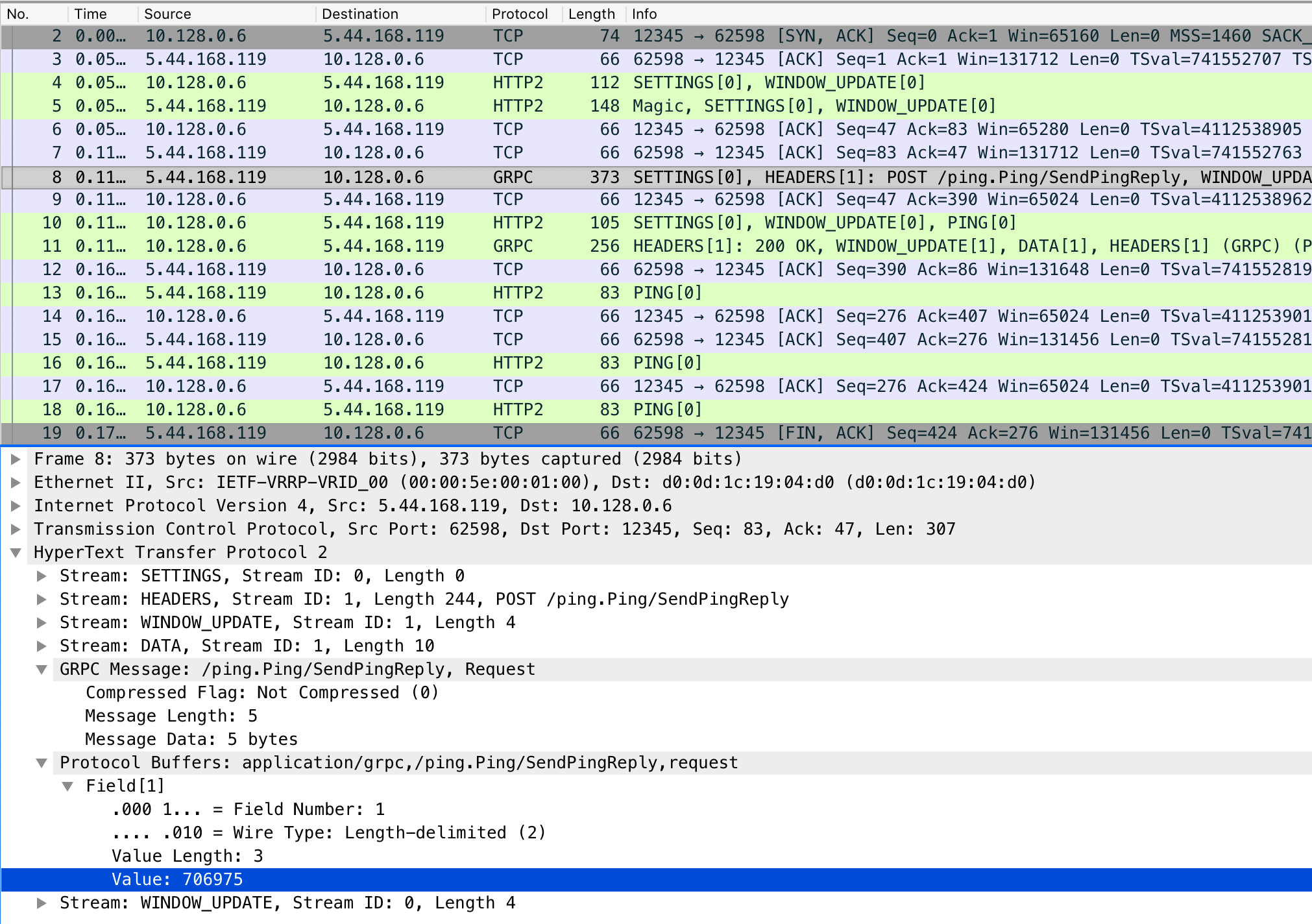
В цикле он будет пытаться выполнить RPC SendPingReply на удалённом хосте 84.201.157.17:12345. В качестве аргумента передаём payload, который считали из аргументов запуска скрипта.
В функции run мы устанавливаем соединение к серверу, подключаем stub и выполняем RPC SendPingReply, которому передаём сообщение PingRequest с тем самым payload.
Мы тут опускаем часть про установку go, protoc, потому что это всё есть в документации grpc.io.
packagemainimport("context""flag""fmt""log""net""google.golang.org/grpc"pb"ping-server/ping")var(port=flag.Int("port",12345,"The server port"))typeserverstruct{pb.UnimplementedPingServer}func(s*server)SendPingReply(ctxcontext.Context,in*pb.PingRequest)(*pb.PingReply,error){log.Printf("Received: %v",in.GetPayload())return&pb.PingReply{Message:in.GetPayload()+"-pong"},nil}funcmain(){flag.Parse()lis,err:=net.Listen("tcp",fmt.Sprintf("10.128.0.6:%d",*port))iferr!=nil{log.Fatalf("failed to listen: %v",err)}s:=grpc.NewServer()pb.RegisterPingServer(s,&server{})log.Printf("server listening at %v",lis.Addr())iferr:=s.Serve(lis);err!=nil{log.Fatalf("failed to serve: %v",err)}}
Вся бизнес логика описана в функции SendPingReply, ожидающей PingRequest, а возвращающей PingReply, в котором мы отправляем сообщение message: payload + “-pong” (GetPayload). Естественно, там может быть более изощрённая логика.
Ну, а в main мы запускаем сервер на адресе 10.128.0.6.
Почему не на 84.201.157.17, на который стучится клиент? Тут без хитростей - это внутренний адрес ВМ, на который натируются все запросы к публичному адресу.
Итак, разобрались с gRPC. Ну, будем так считать, по крайней мере.
Внутри гугла gRPC удалось адаптировать даже к задачам сети. То есть gRPC стал единым интерфейсом взаимодействия между разными компонентами во всей компании (или одним из - мы не знаем).
gNMI довольно новый протокол. Про него нет страницы на вики, довольно мало материалов и мало кто рассказывает о том, как его использует в своём проде.
Он не является стандартом согласно любым организациям и RFC, но его спецификация описана на гитхабе.
Что нам важно знать о нём для начала? gRPC Network Management Interface.
Это протокол управления сетевыми устройствами, использующий gRPC как фреймворк: транспорт, режимы взаимодействия (унарный и все виды стриминга), механизмы маршаллинга данных, прото-файлы для описания спецификаций.
В качестве модели данных он может использовать YANG (а может и не использовать - в протобафы можно же засунуть всё, что угодно).
Как того требует gRPC, на сетевом устройстве запускается сервер, на системе управления - клиент. На обеих сторонах должна быть одна спецификация, одна модель данных.
Здесь каждый RPC расписан на сообщения и типы данных, и указаны ссылки на прото-спеки и документацию.
Не могу сказать, что это удобное место для того, чтобы начать знакомиться с gNMI, но вы точно к нему ещё много раз вернётесь, если сядете на gNMI.
Предлагаю попробовать на практике вместо теорий.
Вообще gNMI, как плоть от плоти gRPC не очень удобен для использования человеком. Прото-файлы пиши, код пиши, исполняй. Нельзя как в REST API просто curl отправить и получить текстовый ответ - это вообще известная боль.
Но для gNMI напридумывали клиентов.
И тут google в лучших традициях делает прекрасные инфраструктурные вещи и ужасный пользовательский интерфейс. gNXI, OpenConfig gNMI CLI client.
Нас и тут спасает Роман Додин, поучаствоваший в создании классного клиента gNMI, совместно с Karim Radhouani - gNMIc.
Устанавливаем по инструкции:
bash-c"$(curl-sLhttps://get-gnmic.kmrd.dev)"
Теперь надо настроить узел.
interface Management1
ip address 192.168.1.11/24
username eucariot secret <SUPPASECRET>
management api gnmi
transport grpc default
ip access-list control-plane-acl-with-restconf-and-gnmi
8 permit tcp any any eq 6030
…
control-plane
ip access-group control-plane-acl-with-restconf-and-gnmi in
И оттуда можно понять, что посмотреть конфигурацию BGP-пиров можно, используя путь "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/config":
В репе ADSM можно найти пример по изменению BGP peer-as.
gNMIc и pyGNMI - это всего лишь частные инструменты для работы через gNMI. Ничто не мешает вам самим реализовать набор методов удобным образом.
Важно здесь заметить то, что у gNMI нет концепции Data Stores и как следствие функционала коммитов конфигурации - мы работаем с сервисом.
gNMI заставляет нас вывернуть привычный взгляд на сеть иголками внутрь. Мы к ней теперь должны относиться как к ещё одному сервису, которым можно легко управлять через единообразный интерфейс. Сам же gNMI обеспечивает транзакционность всех изменений, передаваемых в одном RPC.
Представьте себе, что вы пишите в базу данных и нужно потом сделать ещё коммит, чтобы эти изменения сохранить - звучит нелогично. Вот так и с сетью - транзакционность есть, коммитов - нет.
Для инфраструктурной команды сеть - это больше не какой-то свой собственный особенный мир, находящийся где-то там за высокой стеной CLI, окружённый рвами, заполненными проприетарным синтаксисом.
Нам следует разделить сетевое устройство, к которому мы всю жизнь относились как к чему-то в целостному, потому что покупаем сразу всё это в сборе, на следующие части:
железный хост - коммутаторы и маршрутизаторы, со всеми их медными и оптическими проводочками, куском кремния под вентилятором и трансиверами,
операционная система - софт, который управляет жизнью железа и запускаемыми приложениями,
приложения, реализующие те или иные сервисы или доступ к ним - аутентификация, интерфейсы, BGP, VLAN’ы, или gNMI, дающий доступ к ним ко всем.
Да, влияние проблем на сетевом устройстве имеет больший охват. Да, можно оторвать себе доступ одним неверным движением. Да, поддержка целевого состояния на все 100% - всё ещё сложная задача.
Но чем, в конце концов это отличается от обычного Linux’а, на котором крутится сервис?
То есть сервисный интерфейс (gNMI, gRPC, REST, NETCONF) следует рассматривать как способ управления собственно сервисами, в то время как для обслуживания хоста никуда не девается SSH+CLI - для отладки, обновления, управления приложениями. Впрочем и тут есть Ansible, Salt. Вот только идеально для этого, чтобы сетевая железка стала по-настоящему открытой - с Linux’ом на борту.
gRPC Network Operations Interface от OpenConfig - набор микросервисов, основанных на gRPC, позволяющих выполнять операционные команды на хостах.
Если проще, то можно запустить ping, traceroute, почистить разные таблицы, сделать Route Refresh BGP-соседу, скопировать файл - всё то, что относится не к конфигурации, а скорее к отладке и эксплуатации.
Начнем с того что под словом “телеметрия” каждый вендор может понимать свое. У Huawei своя реализация поверх gRPC (местами даже платная!), у Cisco есть Model-driven Telemetry (например Cisco Model-Driven Telemetry (MDT) Input Plugin), у Juniper тоже есть своя реализация - JTI. Последние два еще параллельно поддерживают gNMI.
Отсюда уже возникает некоторая путаница, с которой разберёмся пониже. Главное - суть одна - устройство само рассылает данные тем клиентам, которые оформили подписку на обновления. Таким образом система мониторинга не тратит такты и RTT на опрос (polling), а всего лишь получает данные на свой интерфейс.
И если частота опроса ограничена единицами-десятками раз в минуту, то стриминг телеметрии вообще нет - устройство может слать хоть по каждому обновлению.
Тут, конечно, нужно быть аккуратным с машстабированием - в случае опроса мы сами управляем тем, сколько данных нужно обработать системой. Объём работы всегда предсказуемый и линейно зависит от числа опрашиваемых узлов. Видим увеличение нагрузки - добавляем ещё экземпляров попрошаек и шардируем нагрузку.
И всё иначе в случае стриминга телеметрии - тут узлы сети могу напихать в коллектор столько, что он не в состоянии обработать. Думать про масштабирование и отказоустойчивость тут придётся до усиленного потовыделения.
Перечисленные выше вендорские телеметрии поддерживают “сжатый формат” протобафов - когда данные представлены в виде структуры, зависимой от вендора, модели и ПО. Для декодирования таких данных нужен специальный вендорский прото-файл. Например, такой. В gNMI же данные в универсальном виде. Это хорошо с точки зрения discovery, так как для запроса нужно найти только путь подписки, но сильно сказывается на размере данных и отсутствии структуры данных (*теоретически можно вывести из моделей).
gNMI чересчур свободен в выборе типа кодирования данных. Можно и Proto и ASCII и даже два вида JSON.
Не предусмотрена “дешевая” отправка. У джуна и у аристы в их собственных протоколах телеметрии есть отправка протобафов в UDP. Это очень дешево для устройства и коллектора и даже может быть реализовано прям на линейной карте (мониторинг микробёрстов, например). При столь частой отправке обновлений разовые потери UDP не страшны.
В gNMI такого нет, но что в нём сделано классно, так это возможность подписаться только на изменения. Рисовать графики только по изменениям так себе идея конечно, но в gNMI можно реализовать такой сценарий: подписываешься на определенные данные, получаешь все значения и записываешь их в свой кеш. Дальше получаешь изменения и опционально периодические полные срезы. Теперь можно периодически отсылать весь кеш в БД и рисовать аккуратные графики.
Если говорить в целом про сбор метрик, то есть смысл использовать то, что поддерживается вендором в первую очередь. SNMP - надежный как швейцарские часы, тонны библиотек для работы с ним, MIBы устоялись и его не стыдно использовать даже в 2022. gNMI крутой, но реализация может подкачать - неизбежны детские болячки типа отсутствия поддержки IPv6 и требования админских прав для получения метрик.
{kind=link}